



When a SQL Server Data File Reaches Maximum Capacity
- Posted in:
- Database Administration
- SQL Server
- Wait Stats

Did you know the maximum capacity of a SQL Server data file is 16 TB? I didn't either. And I recently learned the hard way. When I got the call, I got as much information as I could, and started sleuthing. There was some blocking, and the head of the blocking chain was consistently the same stored procedure--let's call it dbo.SaveData. I ran a few more scripts to find "expensive" queries via sys.dm_exec_query_stats and sys.dm_exec_procedure_stats and sure enough, dbo.SaveData had its fingerprints there too.
I was told there had been a not-so-recent failover. The maintenance jobs for index defragmentation had not been run in a while. This particular instance used maintenance plans along with index reorganization operations. There were no statistics updates. Index reorganizations had been started manually and were still running. Based on past performance, I was told it could take around 24 hours to complete.
Execution plans for the stored proc showed SELECTS as really efficient compared to INSERTS, UPDATES, and DELETES. There were a couple of tables involved: a queue table that had less than 100 rows, and a permanent table that had more than 50 million. The permanent table (let's call it dbo.Docs) had a UNNIQUEIDENTIFIER column as the clustered index with a 90% FILL FACTOR. The table was in the PRIMARY FILEGROUP on D:\, however, there was also an IMAGE column that was on a separate FILEGROUP on G:\. Normally I'd be very suspicious of any table with a UNIQUEIDENTIFIER column as a cluster key. But this table only had three columns: the third column was a ROWVERSION data type. Even if there were crazy page splits happening, each row only required 24 bytes for the UNIQUEIDENTIFER/ROWVERSION columns (assuming the IMAGE column was always stored off-row in the other FILEGROUP). I didn't look up the full calculation, but I think that's something in the neighborhood of 300 rows per page. As slow as the system was running, it would have been a miracle if there were 300 inserts in an hour.
There was another DMV I had checked a number of times: sys.dm_exec_requests. I was looking for open transactions. I found them on a regular basis, but they would eventually "close" (presumably commits). I also noticed SOS_SCHEDULER_YIELD waits were showing up almost every time dbo.SaveData was executed. I knew there were a couple of common knee-jerk reactions associated with that wait type. I also remember looking that one up on SQLSkills on numerous occasions. This wait type often is related to SQL doing a lot of scanning of pages in memory.
Everything I've covered so far was what I found before I took action. So, what did I do? I humbly admit I had no idea what the problem was. My first order of business was to update statistics on the queue table. I felt confident that this was very likely unnecessary because of the small number of rows in the table. But because it was so small, I figured why not? Then I updated statistics on dbo.Docs. That took a long time. Afterwards, there was no appreciable change in performance. Nor was there a change in execution plans for the stored proc. I took multiple second looks at the stored proc, its code, and its execution plan. I didn't sense any code smells to indicate parameter sniffing. Nor were there signs of implicit conversions in the execution plans. There was about 0.1% fragmentation on the clustered index of dbo.Docs.
I could see that most of the stored proc execution calls were coming from the same server, which was a processing server running a web service. The customer decided to shut down the service and have a quick discussion with his dev team to see if there had been any recent changes deployed. We called it a night. I got a text the next morning. The server was rebooted, and performance had improved noticeably. None to my surprise, I got another call later that day: performance had deteriorated again.
I got back online and looked at all the same things I'd looked at before and still was puzzled. Something new I noticed, though was a huge volume of logical reads for the INSERT statement to dbo.Docs. The logical_reads column of sys.dm_exec_requests was showing a ginormous number, possibly as much as 6 digits worth of page reads. I knew that meant something, but I didn't know what. I mentioned this to the client and they told me the G:\ drive was getting thrashed.
Hmmm. Maybe the page splits that I dismissed earlier *were* a problem. I wasn't sure how the off-row IMAGE data storage was handled. A "document" was often several megabytes, so if it was stored on pages like other data, each would span multiple pages. That didn't sound like it would lead to page splits. But even as I write this, I'm not sure. I had another thought at this point: could the autogrowth events be happening in really small increments like 1 MB? Is IFI enabled for the Windows account running the database engine service? I checked the file properties for probably the second or third time. Yes, I had remembered correctly. Autogrowth was set to 5 GB. I also learned IFI was indeed enabled. I ran a query to check free space in the data file on G:\. Wait! What's this?
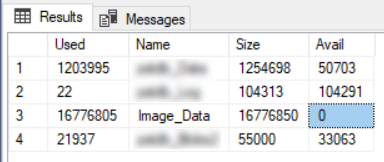
Why is there zero free space available in that file? I suppose that's technically possible, if not unlikely. And then I looked at that file size. It's a lot larger than the others. If it had started with 15 or 17, I might have thought nothing further. But 16... That's 2 to the 4th power. Did I hit an upper limit on data file size? Why yes, yes I did! After a few attempts, I was able to add another file to the existing FILEGROUP. Within moments, performance resumed to "normal".
Looking back I feel humbled that it took me so long to find the problem. I've come away from the experience thinking a better DBA might have solved it much more quickly. Heck, in a way I got lucky there at the end. I almost didn't recognize the solution when it was in front of me. I was very close to moving on. I suspect when the existing file could no longer grow, there was still some internal free space due to the 90% FILL FACTOR. SQL Server performed an enormous amount of IO (which included all those logical reads I observed) trying to find space for new rows in that 10% of unallocated space. I'm also assuming it was widely scattered and non-contiguous. Every insert may have led to a full table scan. I wish I could prove that supposition. It's speculation at this point. While there is still some frustration, I am pleased that I found the solution. The client (and their clients) are all happy now. I should also add I found no evidence in the error log of any issue with the maxed out data file. When I get a chance, I'll review sys.messages to see if there's any related error message. I'm not optimistic.
So that's what happened to me when a SQL Server data file reached it's maximum capacity. What would you have done? Where do you think I went wrong? What did I get right? Comments welcome!
Comments