



OPENJSON Performance
- Posted in:
- SQL Server
- JSON
- T-SQL

Support for JSON data has been around in SQL Server for a while now, starting with SQL 2016. The OPENJSON rowset function is the built-in function that allows you to natively convert JSON text into a set of rows and columns. There are two options for using OPENJSON: with the default schema or with an explicit schema. There are performance implications for each, which I'll review with some examples.
Default Schema
With the default schema, the data returned by OPENJSON depends on the input data. A JSON object returns rows of key/value pairs, and a JSON array returns rows of array elements. All of the JSON files used in the examples shown here are comprised of JSON array data. (They're available on Github if you'd like to download and run the demos.) Let's take a look at the first JSON data file. Here's a sample of what the data looks like:
[
{"WidgetNumber":"000021","Quantity":{"Warehouse18":0,"Warehouse1":0,"Warehouse36":0,"Warehouse22":0,"Warehouse26":0,"Warehouse29":0,"Warehouse21":0,"Warehouse3":0,"Warehouse4":0,"Warehouse11":0,"Warehouse23":0,"Warehouse24":0}},
{"WidgetNumber":"000119","Quantity":{"Warehouse24":0,"Warehouse18":0,"Warehouse4":0,"Warehouse3":4,"Warehouse22":0,"Warehouse26":0,"Warehouse23":0,"Warehouse11":0,"Warehouse1":0,"Warehouse36":4,"Warehouse21":1,"Warehouse29":0}},
{"WidgetNumber":"0001223657","Quantity":{"Warehouse18":0,"Warehouse21":0,"Warehouse24":0,"Warehouse36":0,"Warehouse23":0,"Warehouse11":0,"Warehouse1":0,"Warehouse22":0,"Warehouse4":0,"Warehouse26":0,"Warehouse29":0,"Warehouse3":0}},
{"WidgetNumber":"00013","Quantity":{"Warehouse21":0,"Warehouse36":0,"Warehouse26":0,"Warehouse29":0,"Warehouse1":0,"Warehouse22":0,"Warehouse18":null,"Warehouse4":0,"Warehouse24":0,"Warehouse3":0,"Warehouse23":0,"Warehouse11":0}},
{"WidgetNumber":"000140","Quantity":{"Warehouse36":0,"Warehouse29":0,"Warehouse11":0,"Warehouse21":0,"Warehouse3":0,"Warehouse18":null,"Warehouse4":0,"Warehouse26":0,"Warehouse24":0,"Warehouse23":0,"Warehouse22":0,"Warehouse1":0}}
]
We can load the JSON data into a variable, pass it to the OPENJSON function, and view the results in SSMS:
DECLARE @Json NVARCHAR(MAX); SELECT @Json = ( SELECT BulkColumn FROM OPENROWSET (BULK 'C:\SQL\ETL\Widgets.v01.json', SINGLE_CLOB) MyFile ); SELECT * FROM OPENJSON(@Json);
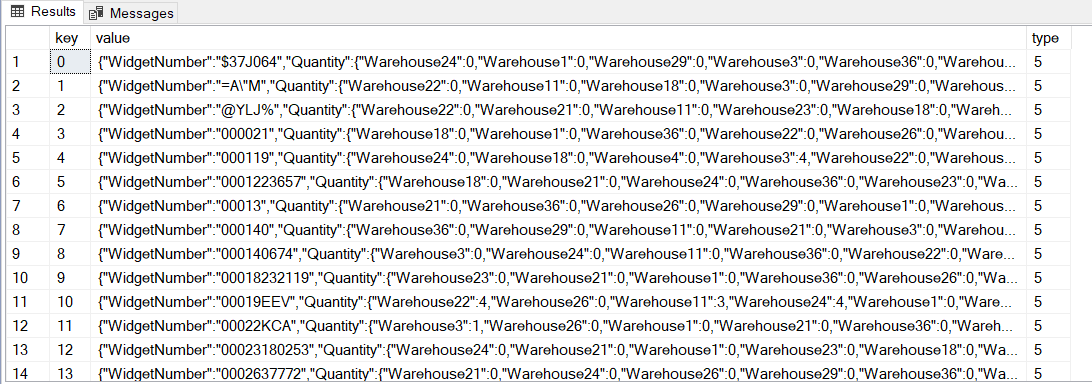
There's about 20 MB of JSON data in the file, and OPENJSON parses it into 90,395 rows. On my laptop, it takes about 550 ms. That seems pretty fast to me. But is it useful? Not so much. We see a WidgetNumber for each row, along with Quantities at different Warehouses. I'd want this further parsed with each item in its own column...you know, like a tabular result set. With the default schema, we'll need some additional help. The JSON_VALUE function can help--it extracts a scalar value from a JSON string.
Let's load the same JSON data into a variable, pass it to the OPENJSON function, augment the query with JSON_VALUE, and view the results in SSMS:
DECLARE @Json NVARCHAR(MAX); SELECT @Json = ( SELECT BulkColumn FROM OPENROWSET (BULK 'C:\SQL\ETL\Widgets.v01.json', SINGLE_CLOB) MyFile ); SELECT JSON_VALUE(value, '$.WidgetNumber') AS WidgetNumber, JSON_VALUE(value, '$.Quantity."Warehouse1"') AS [Warehouse1], JSON_VALUE(value, '$.Quantity."Warehouse11"') AS [Warehouse11], JSON_VALUE(value, '$.Quantity."Warehouse18"') AS [Warehouse18], JSON_VALUE(value, '$.Quantity."Warehouse21"') AS [Warehouse21], JSON_VALUE(value, '$.Quantity."Warehouse22"') AS [Warehouse22], JSON_VALUE(value, '$.Quantity."Warehouse23"') AS [Warehouse23], JSON_VALUE(value, '$.Quantity."Warehouse24"') AS [Warehouse24], JSON_VALUE(value, '$.Quantity."Warehouse26"') AS [Warehouse26], JSON_VALUE(value, '$.Quantity."Warehouse29"') AS [Warehouse29], JSON_VALUE(value, '$.Quantity."Warehouse3"') AS [Warehouse3], JSON_VALUE(value, '$.Quantity."Warehouse36"') AS [Warehouse36], JSON_VALUE(value, '$.Quantity."Warehouse4"') AS [Warehouse4] FROM OPENJSON(@Json);
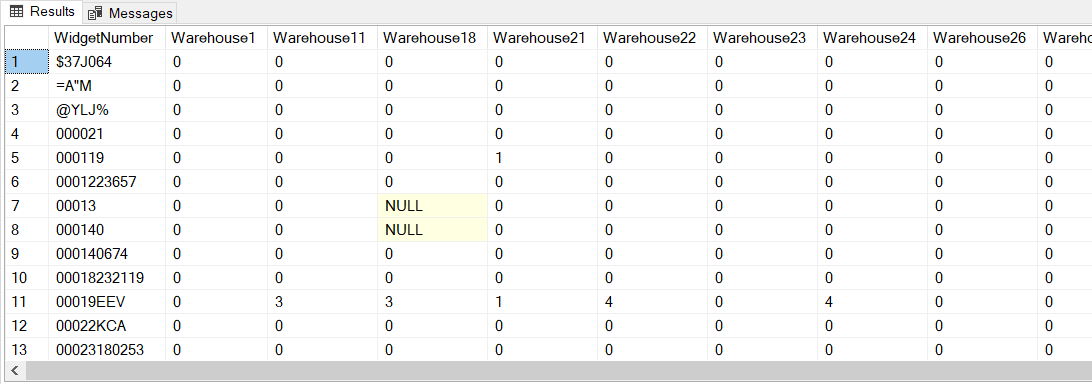
Ah, that looks better! Just what I wanted. But we took a bit of a performance hit: here, OPENJSON parsed the same data into 90,395 rows in 3,850 ms.
Explicit Schema
We can bring down CPU time for the OPENJSON function if we use an Explicit Schema. It produces a tabular result set like in the previous example. But instead of using functions like JSON_VALUE, the format is specified in a WITH clause. Let's load the JSON data into a variable again, pass it to the OPENJSON function, specify the output format (columns, data types, and JSON paths) in a WITH clause, and view the results in SSMS:
DECLARE @Json VARCHAR(MAX); SELECT @Json = ( SELECT BulkColumn FROM OPENROWSET (BULK 'C:\SQL\ETL\Widgets.v01.json', SINGLE_CLOB) MyFile ); SELECT * FROM OPENJSON(@Json) WITH ( WidgetNumber VARCHAR(128) '$.WidgetNumber', [Warehouse1] INT '$.Quantity."Warehouse1"', [Warehouse11] INT '$.Quantity."Warehouse11"', [Warehouse18] INT '$.Quantity."Warehouse18"', [Warehouse21] INT '$.Quantity."Warehouse21"', [Warehouse22] INT '$.Quantity."Warehouse22"', [Warehouse23] INT '$.Quantity."Warehouse23"', [Warehouse24] INT '$.Quantity."Warehouse24"', [Warehouse26] INT '$.Quantity."Warehouse26"', [Warehouse29] INT '$.Quantity."Warehouse29"', [Warehouse3] INT '$.Quantity."Warehouse3"', [Warehouse36] INT '$.Quantity."Warehouse36"', [Warehouse4] INT '$.Quantity."Warehouse4"' );
We get the same output as in the previous example. And performance improves quite a bit with average CPU time down from 3,850 ms to 1,440 ms. I've seen similar results in many different scenarios using an Explicit Schema vs a Default Schema that uses JSON_VALUE. It's a big performance gain for a small code change.
Execution plans for the Default Schema query (parsed with JSON_VALUE) and the Explicit Schema query look similar. It's interesting that the OPENJSON function is referred to in the plan XML as OPENJSON_DEFAULT and OPENJSON_EXPLICIT respectively. What really caught my eye was the Estimated Row Size (4,035 bytes vs 124 bytes) and the Actual Data Size (348 MB vs 11 MB).
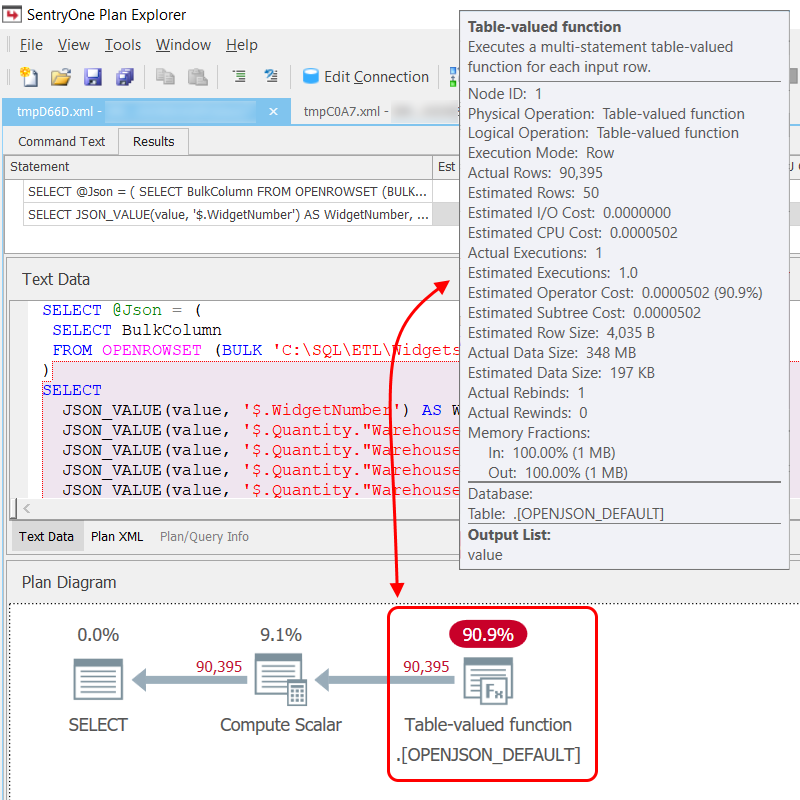
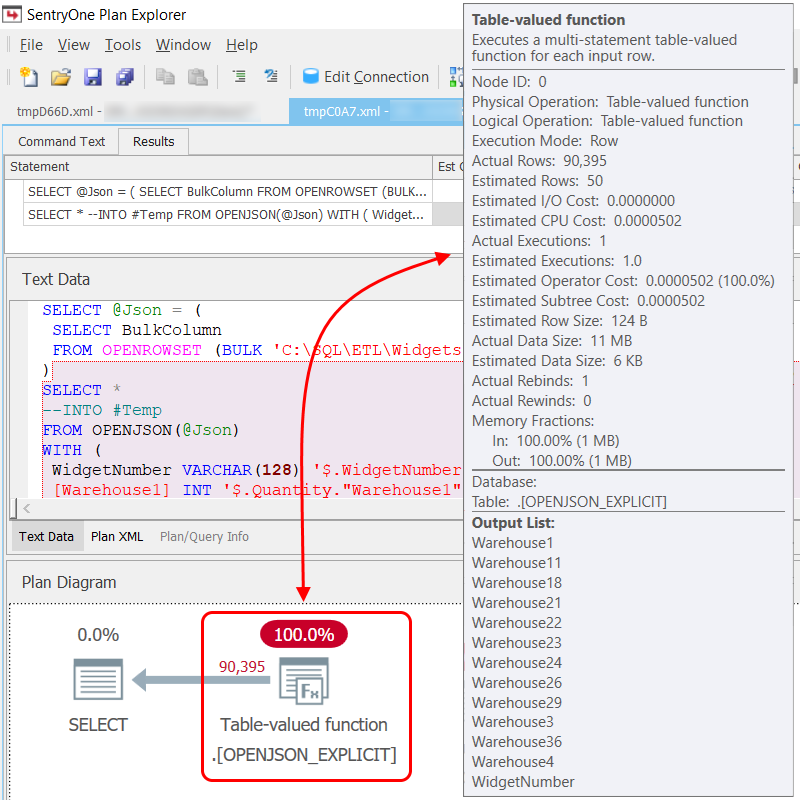
Less Is More
Often, switching to an Explicit Schema is all the performance gain that's needed. If you need to eke out additional performance and drop the CPU time as low as possible, there are some other options...if you have control over the format of the JSON data you're ingesting. For example, removing all occurrences of the word "Warehouse" from the JSON data file leaves behind just the warehouse number, and reduces the file size from 20 MB down to 10½ MB. To use it, we'll have to modify the WITH clause to reflect the change in JSON paths. Here's a sample of what the second JSON data file contents looks like, along with our new query:
[
{"WidgetNumber":"000021","Quantity":{"18":0,"1":0,"36":0,"22":0,"26":0,"29":0,"21":0,"3":0,"4":0,"11":0,"23":0,"24":0}},
{"WidgetNumber":"000119","Quantity":{"24":0,"18":0,"4":0,"3":4,"22":0,"26":0,"23":0,"11":0,"1":0,"36":4,"21":1,"29":0}},
{"WidgetNumber":"0001223657","Quantity":{"18":0,"21":0,"24":0,"36":0,"23":0,"11":0,"1":0,"22":0,"4":0,"26":0,"29":0,"3":0}},
{"WidgetNumber":"00013","Quantity":{"21":0,"36":0,"26":0,"29":0,"1":0,"22":0,"18":null,"4":0,"24":0,"3":0,"23":0,"11":0}},
{"WidgetNumber":"000140","Quantity":{"36":0,"29":0,"11":0,"21":0,"3":0,"18":null,"4":0,"26":0,"24":0,"23":0,"22":0,"1":0}}
]
DECLARE @Json VARCHAR(MAX); SELECT @Json = ( SELECT BulkColumn FROM OPENROWSET (BULK 'C:\SQL\ETL\Widgets.v02.json', SINGLE_CLOB) MyFile ); SELECT * FROM OPENJSON(@Json) WITH ( WidgetNumber VARCHAR(128) '$.WidgetNumber', [Warehouse1] INT '$.Quantity."1"', [Warehouse11] INT '$.Quantity."11"', [Warehouse18] INT '$.Quantity."18"', [Warehouse21] INT '$.Quantity."21"', [Warehouse22] INT '$.Quantity."22"', [Warehouse23] INT '$.Quantity."23"', [Warehouse24] INT '$.Quantity."24"', [Warehouse26] INT '$.Quantity."26"', [Warehouse29] INT '$.Quantity."29"', [Warehouse3] INT '$.Quantity."3"', [Warehouse36] INT '$.Quantity."36"', [Warehouse4] INT '$.Quantity."4"' );
The reduction in JSON data size brings CPU time down from 1,440 ms to 960 ms. A decent gain that might matter at a much larger scale.
Could you live without the full words "WidgetNumber" and "Quantity"? Those could be replaced with "W" and "Q". That further reduces the size of the JSON data file from 10½ MB to 9 MB. Here's a sample of what the third JSON data file contents looks like, along with our new query and a modified WITH clause:
[
{"W":"000021","Q":{"18":0,"1":0,"36":0,"22":0,"26":0,"29":0,"21":0,"3":0,"4":0,"11":0,"23":0,"24":0}},
{"W":"000119","Q":{"24":0,"18":0,"4":0,"3":4,"22":0,"26":0,"23":0,"11":0,"1":0,"36":4,"21":1,"29":0}},
{"W":"0001223657","Q":{"18":0,"21":0,"24":0,"36":0,"23":0,"11":0,"1":0,"22":0,"4":0,"26":0,"29":0,"3":0}},
{"W":"00013","Q":{"21":0,"36":0,"26":0,"29":0,"1":0,"22":0,"18":null,"4":0,"24":0,"3":0,"23":0,"11":0}},
{"W":"000140","Q":{"36":0,"29":0,"11":0,"21":0,"3":0,"18":null,"4":0,"26":0,"24":0,"23":0,"22":0,"1":0}}
]
DECLARE @Json VARCHAR(MAX); SELECT @Json = ( SELECT BulkColumn FROM OPENROWSET (BULK 'C:\SQL\ETL\Widgets.v03.json', SINGLE_CLOB) MyFile ); SELECT * FROM OPENJSON(@Json) WITH ( WidgetNumber VARCHAR(128) '$.W', [Warehouse1] INT '$.Q."1"', [Warehouse11] INT '$.Q."11"', [Warehouse18] INT '$.Q."18"', [Warehouse21] INT '$.Q."21"', [Warehouse22] INT '$.Q."22"', [Warehouse23] INT '$.Q."23"', [Warehouse24] INT '$.Q."24"', [Warehouse26] INT '$.Q."26"', [Warehouse29] INT '$.Q."29"', [Warehouse3] INT '$.Q."3"', [Warehouse36] INT '$.Q."36"', [Warehouse4] INT '$.Q."4"' );
The further reduction in JSON data size brings CPU time down from 960 ms to 860 ms. A more nominal gain than our previous optimizations.
Comments